
基于粒子滤波和三维变分混合数据同化方法的构建与理想实验验证
|
姚长坤(1999—), 男, 黑龙江省绥化市人, 硕士研究生, 从事数据同化相关算法研究。email: |
Copy editor: 孙翠慈
收稿日期: 2023-04-25
修回日期: 2023-06-08
网络出版日期: 2023-06-26
Construction and ideal experimental verification of hybrid data assimilation method based on particle filter and 3Dvar
Copy editor: SUN Cuici
Received date: 2023-04-25
Revised date: 2023-06-08
Online published: 2023-06-26
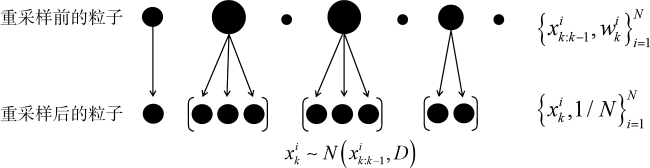
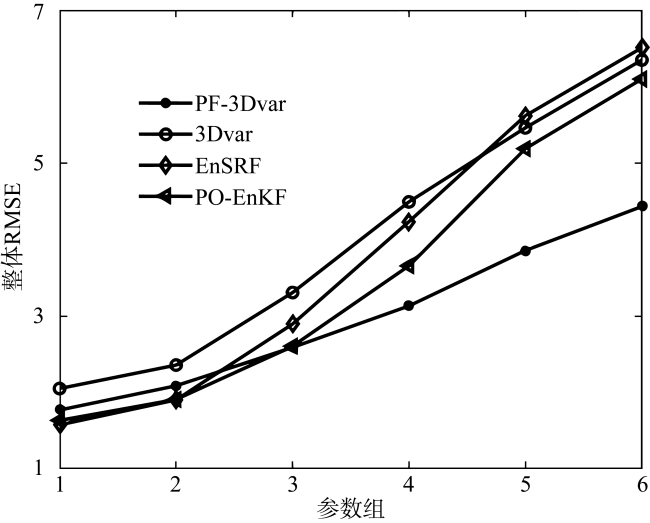
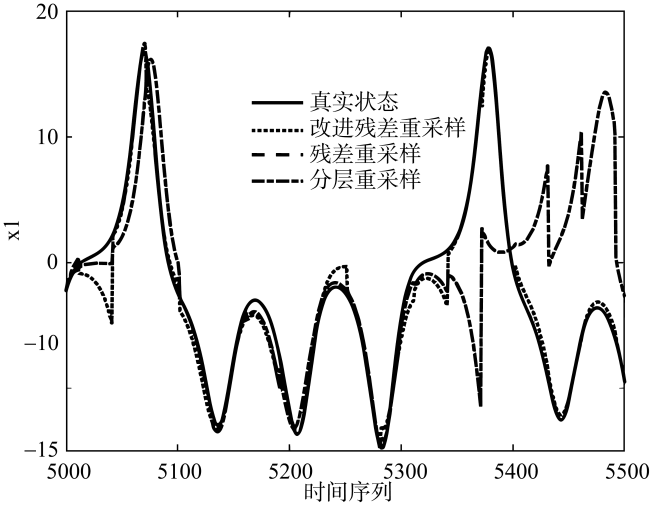
本文基于粒子滤波和三维变分设计了一种新的混合数据同化方法。新方法通过粒子滤波的最优估计生成具有背景误差信息的集合扰动, 从而为三维变分提供流依赖的背景误差协方差。粒子退化一直是粒子滤波应用于数据同化领域的主要阻碍。为了让混合方法更好地发挥作用, 针对粒子退化问题, 本文提出了一种改进的残差重采样方法, 通过在正态分布中采样粒子, 解决了退化导致的粒子缺乏多样性。在理想lorenz-63模型上进行数据同化实验, 结果表明, 新方法在模型误差较大的情况下效果优于集合变换三维变分方法(ensemble transform Kalman filter-three-dimensional variational method, ETKF- 3Dvar), 并且随着模型误差不断增大, 新方法也同样优于传统数据同化方法。改进的残差重采样在与分层重采样和一般残差重采样的对比实验中, 在给定时间窗口内可以保证同化结果稳定, 而其他两种方法的同化结果都出现了较大偏差。
姚长坤 , 魏琨 . 基于粒子滤波和三维变分混合数据同化方法的构建与理想实验验证[J]. 热带海洋学报, 2024 , 43(1) : 56 -63 . DOI: 10.11978/2023052
In this paper, a new hybrid data assimilation method is designed based on particle filter and 3Dvar. The new method generates an ensemble deviation with background error information through an optimal estimation of particle filter, thus providing flow-dependent background error covariance for 3Dvar. Particle degeneracy has always been the main obstacle of particle filtering in data assimilation field. In order to make the hybrid method work better, an improved residual resampling method is proposed to solve the problem of particle degeneracy. By sampling particles in the normal distribution, the lack of particle diversity caused by degeneracy is solved. Data assimilation experiments were tested on the ideal lorenz-63 model. The results show that the new method is better than the ETKF-3Dvar method when the model error is large, and as the model error increases, the new method is also better than the traditional data assimilation method. In the comparison experiment with hierarchical resampling and general residual resampling, the improved residual resampling method can ensure the stability of the assimilation results within a given time window, while the other two methods have a large deviation in the assimilation results.
Key words: hybrid data assimilation; particle filter; 3Dvar; residual resampling
表1 六组扰动依次增大的模型参数Tab.1 Six groups of model parameters with successively increasing perturbations |
| 参数 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| $a$ | 10.1 | 10.6 | 11.1 | 11.6 | 12.1 | 12.6 |
| $b$ | 28.1 | 28.6 | 29.1 | 29.6 | 30.1 | 30.6 |
| $c$ | 2.7 | 3.2 | 3.7 | 4.2 | 4.7 | 5.2 |
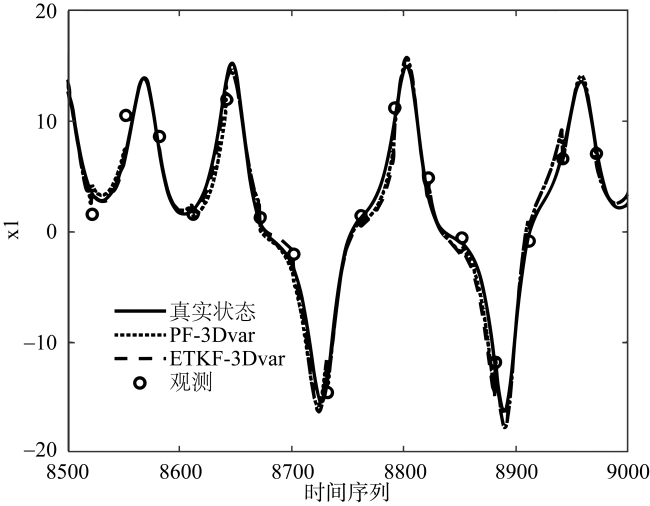
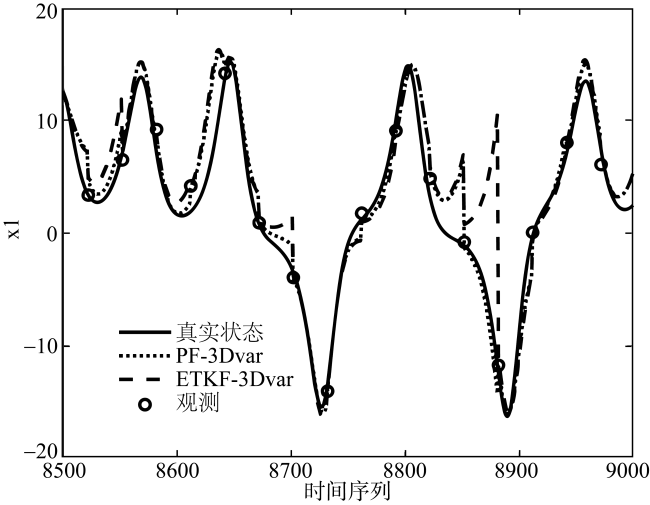
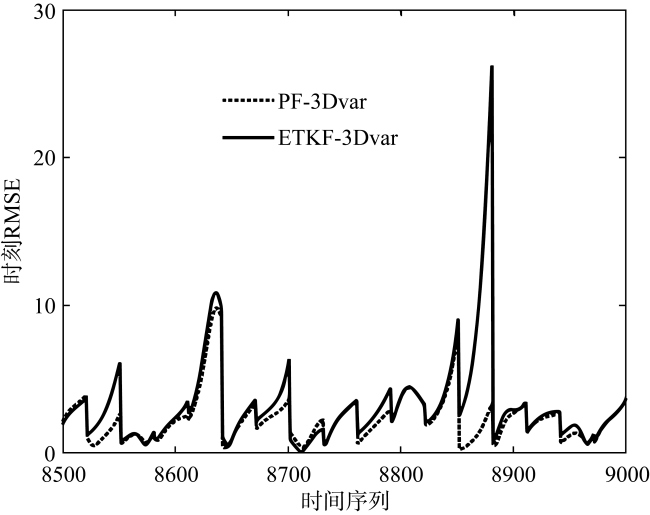
图3 两种混合同化方法在模型误差较大时, 8500到9000步上的同化结果对比图Fig. 3 Comparison of assimilation results of the two hybrid assimilation methods at 8500 to 9000 steps when the model error is relatively large |
| [1] |
冯驰, 赵娜, 王萌, 2010. 一种改进残差重采样算法的研究[J]. 哈尔滨工程大学学报, 31(1): 120-124.
|
| [2] |
李新, 黄春林, 车涛, 2007. 中国陆面数据同化系统研究的进展与前瞻[J]. 自然科学进展, 17 (2): 163-173.
|
| [3] |
王法胜, 鲁明羽, 赵清杰, 等, 2014. 粒子滤波算法[J]. 计算机学报, 37(8): 1679-1694.
|
| [4] |
吴新荣, 韩桂军, 李冬, 等, 2011. 集合滤波和三维变分混合数据同化方法研究[J]. 热带海洋学报, 30(6): 24-30.
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}