
基于空间插值的不规则海洋地质样品测试分析数据聚类算法研究
|
邵长高(1983—), 男, 博士, 正高级高工, 地质信息技术专业, 主要研究方向为海洋大数据分析、海洋遥感监测和海洋沉积地球化学等。email: |
Copy editor: 殷波
收稿日期: 2023-05-13
修回日期: 2023-06-19
网络出版日期: 2023-06-25
基金资助
三亚崖州湾科技城管理局科技计划项目(SKJC-2022-01-001)
海域监测应用项目(2022R-SYS25-03)
Clustering algorithm of irregular marine geological sampling data based on spatial interpolation
Copy editor: YIN Bo
Received date: 2023-05-13
Revised date: 2023-06-19
Online published: 2023-06-25
Supported by
Sanya Yazhou Bay Science and Technology City Administration 2022 Annual Science and Technology Plan Project Grant(SKJC-2022-01-001)
Sea Area Monitoring Application Project(2022R-SYS25-03)
邵长高 , 严镔 , 陈秋 . 基于空间插值的不规则海洋地质样品测试分析数据聚类算法研究[J]. 热带海洋学报, 2024 , 43(2) : 166 -172 . DOI: 10.11978/2023062
A large number of core sampling data were obtained from marine geological survey. Different kinds of measurement data have different sampling depths, resulting in irregularly scattered distribution of 3D geological sampling. The irregularly scattered data on the three dimensional were not able being clustered using traditional clustering algorithm especially in the case of big data analysis. The present study designs a clustering algorithm for irregular geological sampling data based on spatial interpolation. In this way, the 3D geological scatter data can be effectively reduced to 2D data, and the computational complexity can be reduced. This algorithm can better solve the classification and analysis of inequality measurement data in geological bodies, and provides a basic technical method for marine geological big data analysis.
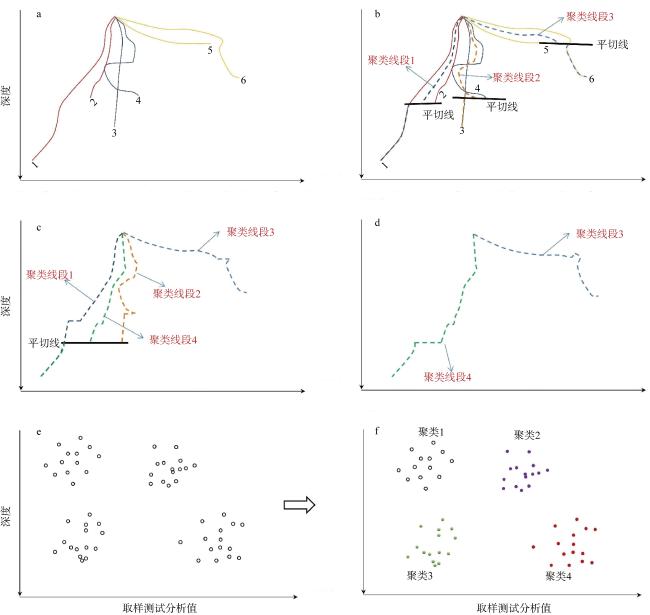
图3 本文设计的解决不规则高维链性数据聚类方法(a~d)和简单数据聚类方法(e、f)a. 线段1、2、3、4、5、6分别表示不同取样深度的柱状样测试结果经过公式(1)插值后形成的线数据; b. 采用凝聚层次聚类, 将距离值最小的线段1和线段2聚类后计算中间值形成聚类线段1, 将距离值最小线段3和线段4聚类后计算中间值形成聚类线段2, 将距离值最小线段5和线段6聚类后计算中间值形成聚类线段3, 平切线为 Fig. 3 The clustering methods designed in this article to solve irregular high-dimensional chain data (a~d) and simple data clustering methods (e, f). (a) The line 1, 2, 3, 4, 5 and 6 in the figure represent the line data formed by interpolation of the core sample results at different sampling depths through equation (1). (b) Agglomerative hierarchical clustering method was used to perform the cluster analysis. The shortest distance of two lines were clustered as one cluster line. For instance, cluster line 1 is calculated from line 1 and line 2 with the middle value of two points in the same depth; cluster line 2 is calculated from line 3 and line 4; and cluster line 3 is calculated from line 5 and line 6. (c) Iterative cluster analysis is performed using cluster lines in |
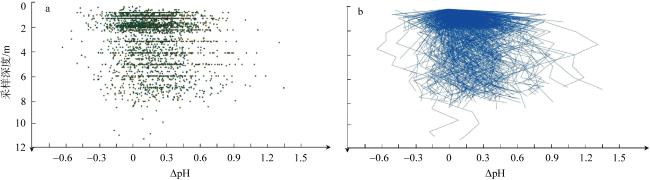
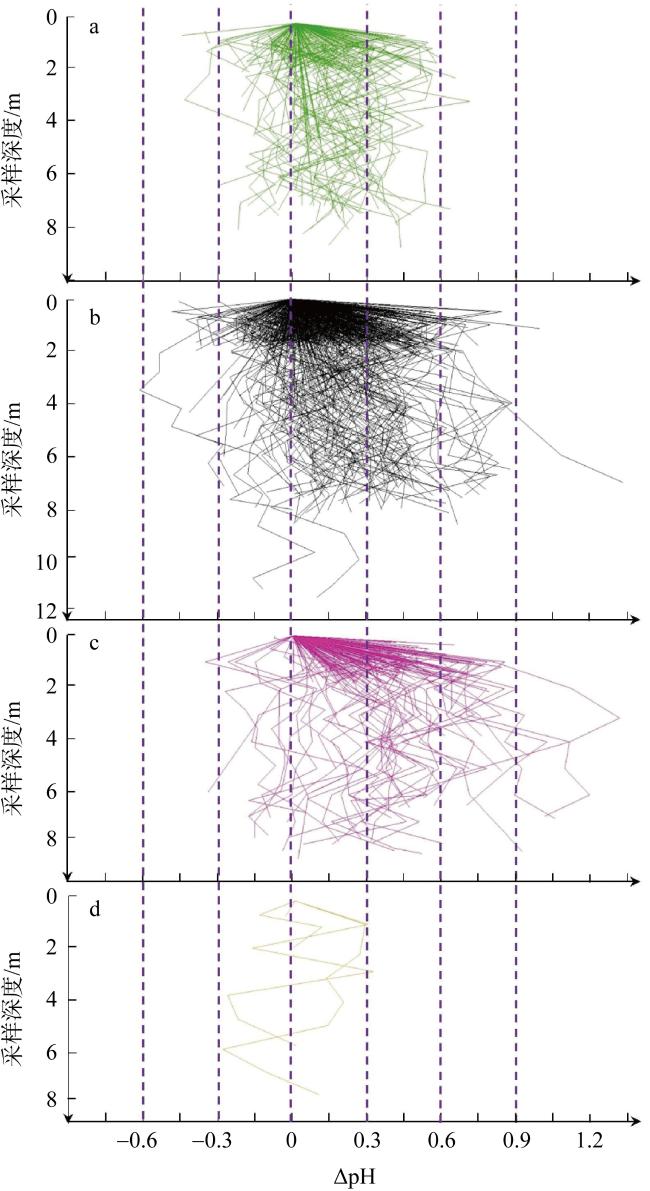
图5 沉积物pH垂直变化特征a. 沉积物深部pH与表层沉积物pH差值随深度的变化特征散点图; b. 对散点进行插值计算后成线的结果 Fig. 5 Vertical variation characteristics of sediment pH. (a) Scatter plot showing the variation characteristics of the pH difference between the deep and surface sediments as a function of depth. (b) According to the method in paper 2, the scattered points in (a) were interpolated to line data for every sediment core |
| [1] |
褚伟, 2022. 多维异构数据的高阶模糊聚类算法研究[D]. 合肥: 合肥工业大学.
|
| [2] |
杜欣, 刘大刚, 倪友聪, 2015. 一种新的并行自动聚类算法: CGC-Cluster[J]. 小型微型计算机系统, 36(6): 1182-1187.
|
| [3] |
贾露, 张德生, 吕端端, 2020. 物理学优化的密度峰值聚类算法[J]. 计算机工程与应用, 56(13): 47-53.
|
| [4] |
靳延安, 刘行军, 2011. 一种改进的层次聚类算法[J]. 武汉理工大学学报(信息与管理工程版), 33(6): 883-886.
|
| [5] |
李瑞佳, 2022. 面向复杂结构数据的聚类算法研究[D]. 成都: 电子科技大学.
|
| [6] |
刘娟, 万静, 2021. 自然反向最近邻优化的密度峰值聚类算法[J]. 计算机科学与探索, 15(10): 1888-1899.
|
| [7] |
邵长高, 谭建军, 荆丽梅, 等, 2009. 海洋小比例尺地图精确测量及计算方法[J]. 地理与地理信息科学, 25(2): 42-45.
|
| [8] |
王芙银, 张德生, 张晓, 2021. 结合鲸鱼优化算法的自适应密度峰值聚类算法[J]. 计算机工程与应用, 57(3): 94-102.
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}