
Journal of Tropical Oceanography >
Rule set and multilayer perceptron based quality control method for Argo temperature data*
Received date: 2023-11-21
Revised date: 2024-01-08
Online published: 2024-01-15
Supported by
National Key Research and Development Program of China(2021YFF0704000)
National Key Research and Development Program of China(2022YFC3106100)
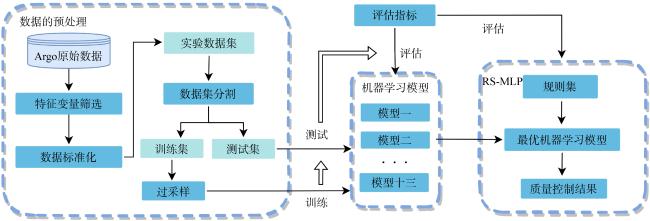
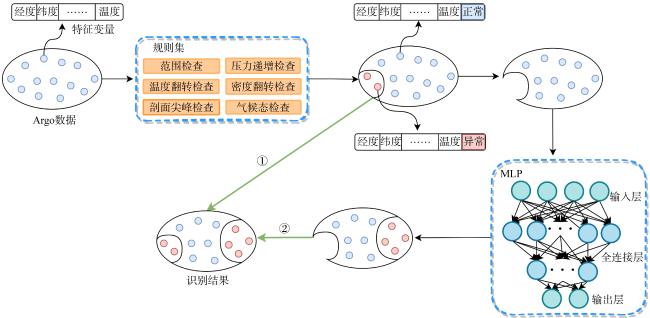
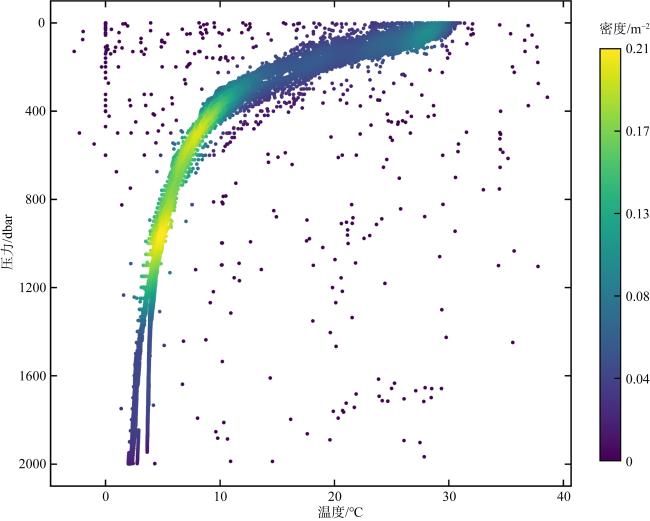
The ocean temperature data plays a crucial role in global ocean observation and climate research. Quality control is essential to ensure the reliability of these data. However, the current recall rate of anomalous data in large datasets is unsatisfactory. This paper proposes a quality control method based on a rule set and multilayer perceptron (RS-MLP), using Argo temperature data. Initially, thirteen machine learning models are compared and analyzed to select the optimal model. Subsequently, a rule set consisting of six rule-based quality control check modules is designed. Finally, the RS-MLP method is constructed by integrating the rule set with the optimal machine learning model, and its performance is evaluated using Argo data from the South China Sea region. The results show that the RS-MLP achieves good performance with true positive rate (TPR), true negative rate (TNR), and area under the receiver operating characteristic (ROC) curve (AUC) reaching 94%, 96%, and 95% respectively in a test set of 351746 temperature data points. The recall rate of anomalous data at different depth levels is stable, demonstrating excellent quality control performance.
Key words: Argo; temperature; machine learning; quality control
QI Huandong , ZHU Cheng , LI Xuchun , JING Xindi , SONG Derui . Rule set and multilayer perceptron based quality control method for Argo temperature data*[J]. Journal of Tropical Oceanography, 2024 , 43(5) : 190 -202 . DOI: 10.11978/2023172
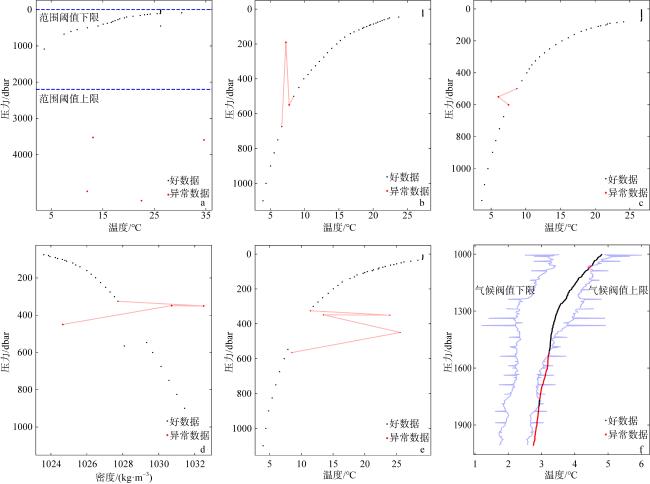
图3 质量控制检查示意图a. 范围检查; b. 压力递增检查; c. 温度翻转检查; d. 密度翻转检查; e. 剖面尖峰检查; f. 气候态检查。图中红色线表示异常数据中异常量的变化, 蓝色线表示所构建的阈值。 Fig. 3 The schematic diagrams of the quality control checks. (a) Range check; (b) increasing pressure check; (c) temperature inversion check; (d) density inversion check; (e) profile spike check; (f) climatology check. The red line in the figure indicates the change in the anomalous data, and the blue line indicates the constructed thresholds |
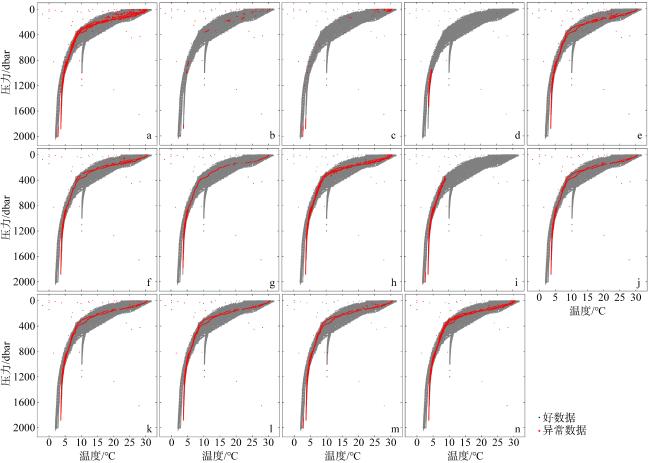
图5 机器学习模型质量控制效果图a. 测试集数据原分布; b. LOF预测结果; c. IF预测结果; d. SVM预测结果; e. DT预测结果; f. KNN预测结果; g. RF预测结果; h. SGD预测结果; i. GNB预测结果; j. XGB预测结果; k. LGB预测结果; l. CatBoost预测结果; m. NGB预测结果; n. MLP预测结果 Fig. 5 Quality control effectiveness of the machine learning models. (a) Original distribution of test set data; (b) predicted results of LOF; (c) predicted results of IF; (d) predicted results of SVM; (e) predicted results of DT; (f) predicted results of KNN; (g) predicted results of RF; (h) predicted results of SGD; (i) predicted results of GNB; (j) predicted results of XGB; (k) predicted results of LGB; (l) predicted results of CatBoost; (m) predicted results of NGB; (n) predicted results of MLP |
表1 机器学习模型的评估指标结果Tab. 1 Results of evaluation metrics for the machine learning models |
| 模型名称 | TPR | TNR |
|---|---|---|
| LOF | 0.94 | 0.05 |
| IF | 0.85 | 0.08 |
| SVM | 0.99 | 0.33 |
| DT | 0.79 | 0.64 |
| KNN | 0.96 | 0.60 |
| RF | 0.99 | 0.48 |
| MLP | 0.94 | 0.90 |
| SGD | 0.86 | 0.88 |
| GNB | 0.90 | 0.72 |
| XGB | 0.98 | 0.61 |
| LGB | 0.98 | 0.66 |
| CatBoost | 0.97 | 0.69 |
| NGB | 0.92 | 0.68 |
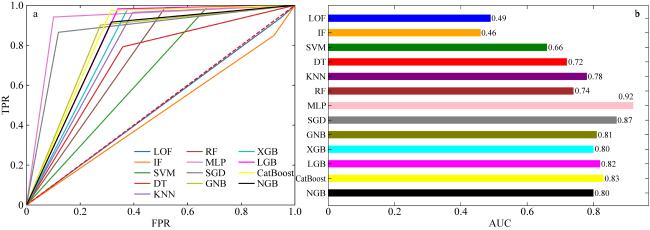
表2 交叉验证法下机器学习模型的评估指标结果Tab.2 Results of evaluation metrics for the machine learning models under the cross-validation approach |
| 模型名称 | TPR | TNR | AUC |
|---|---|---|---|
| LOF | 0.94 | 0.09 | 0.52 |
| IF | 0.95 | 0.06 | 0.51 |
| SVM | 0.99 | 0.28 | 0.63 |
| DT | 0.99 | 0.59 | 0.79 |
| KNN | 0.98 | 0.64 | 0.81 |
| RF | 0.99 | 0.55 | 0.77 |
| MLP | 0.92 | 0.89 | 0.91 |
| SGD | 0.72 | 0.81 | 0.76 |
| GNB | 0.86 | 0.60 | 0.73 |
| XGB | 0.90 | 0.56 | 0.72 |
| LGB | 0.98 | 0.74 | 0.86 |
| CatBoost | 0.96 | 0.81 | 0.89 |
| NGB | 0.96 | 0.74 | 0.85 |
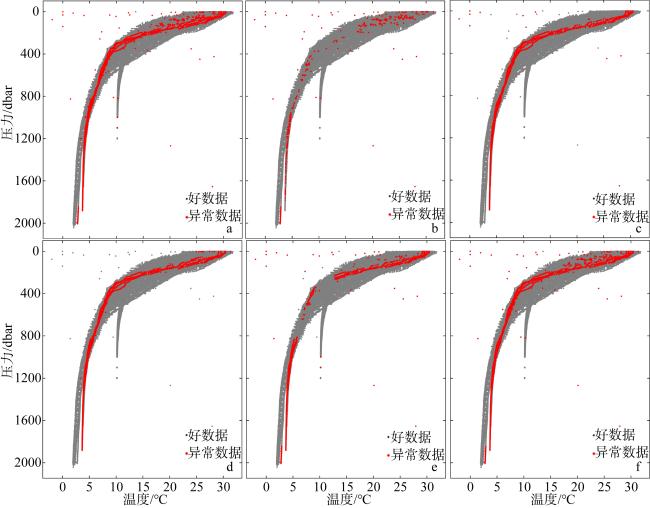
图7 RS-MLP质量控制效果图a. 测试集数据原分布; b. 规则集预测结果; c. MLP预测结果; d. MFP预测结果; e. GCH预测结果; f. RS-MLP预测结果 Fig. 7 Quality control effectiveness of RS-MLP. (a) Original distribution of test set data; (b) predicted results of rule set; (c) predicted results of MLP; (d) predicted results of MFP; (e) predicted results of GCH; (f) predicted results of RS-MLP |
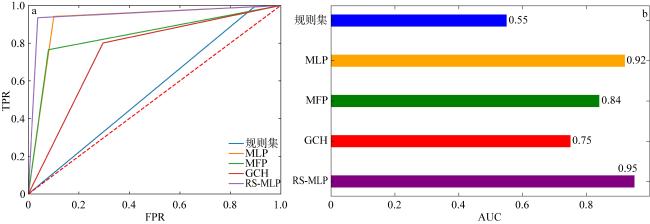
表4 交叉验证法下RS-MLP的评估指标结果Tab. 4 Results of evaluation metrics for RS-MLP under the cross-validation approach |
| 模型名称 | TPR | TNR | AUC |
|---|---|---|---|
| 规则集 | 0.99 | 0.12 | 0.55 |
| MLP | 0.92 | 0.89 | 0.91 |
| MFP | 0.69 | 0.60 | 0.64 |
| GCH | 0.64 | 0.65 | 0.65 |
| RS-MLP | 0.92 | 0.95 | 0.94 |
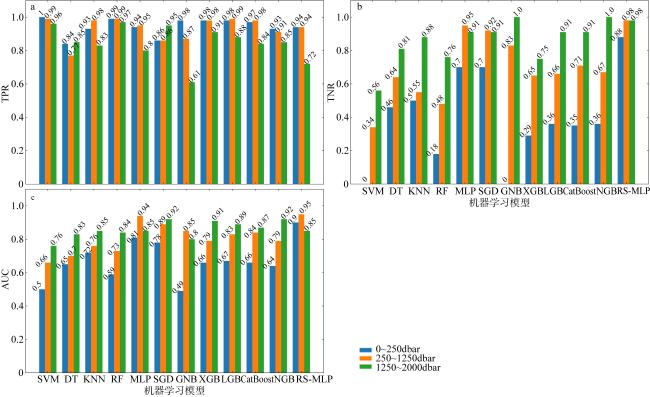
图10 机器学习模型在不同深度下的评估指标结果a. 不同深度TPR结果; b. 不同深度TNR结果; c. 不同深度AUC结果 Fig. 10 Results of the evaluation metrics for the machine learning models at different depths. (a) Results of the TPR at different depths; (b) results of the TNR at different depths; (c) results of the AUC at different depths |
| [1] |
蒋华, 武尧, 王鑫, 等, 2019. 改进K均值聚类的海洋数据异常检测算法研究[J]. 计算机科学, 46(7): 211-216.
|
| [2] |
刘玉龙, 王国松, 侯敏, 等, 2021. 基于深度学习的海温观测数据质量控制应用研究[J]. 海洋通报, 40(3): 283-291.
|
| [3] |
刘增宏, 李兆钦, 卢少磊, 等, 2021. 全球海洋Argo温盐度剖面散点数据集[J]. 全球变化数据学报(中英文), 5(3): 312-321, 451-460.
|
| [4] |
卢少磊, 孙朝辉, 刘增宏, 等, 2016. COPEX和HM2000与APEX型剖面浮标比测试验及资料质量评价[J]. 海洋技术学报, 35(1): 84-92.
|
| [5] |
沈锐, 王德亮, 刘增宏, 等, 2019. HM2000型剖面浮标的主要特征及其应用[J]. 数字海洋与水下攻防, 2(2): 20-27.
|
| [6] |
石洪波, 陈雨文, 陈鑫, 2019. SMOTE过采样及其改进算法研究综述[J]. 智能系统学报, 14(6): 1073-1083.
|
| [7] |
谭哲韬, 张斌, 吴晓芬, 等, 2022. 海洋观测数据质量控制技术研究现状及展望[J]. 中国科学: 地球科学, 52(3): 418-437.
|
| [8] |
王东晓, 邱春华, 舒业强, 等, 2022. 南海环流多尺度动力过程演变特征与机制研究进展[J]. 海洋科学进展, 40(4): 605-623.
|
| [9] |
许自舟, 宋德瑞, 赵辉, 等, 2009. 海洋环境监测数据质量计算机控制方法研究[J]. 海洋环境科学, 28(3): 320-323.
|
| [10] |
杨剑锋, 乔佩蕊, 李永梅, 等, 2019. 机器学习分类问题及算法研究综述[J]. 统计与决策, 35(6): 36-40.
|
| [11] |
张桐, 2018. 基于Argo数据的海洋温度预测方法研究[D]. 长春: 吉林大学: 1-2.
|
| [12] |
张雪薇, 韩震, 2022. Argo温度数据的ConvGRU模型预测分析[J]. 海洋环境科学, 41(4): 628-635.
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
Intergovernmental Oceanographic Commission, 2010. GTSPP real-time quality control manual. Revised edition 2010[Z]. Paris: United Nations Educational, Scientific and Cultural Organization.
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}